¿Qué dice hoy la prensa? Topic modeling con R
En el último post estuve jugando un poco con tidytext y algunas otras herramientas que ofrece R en cuanto a text mining se refiere. Una de las cosas que quedó pendiente fue hacer algo de topic modeling, para lo cual escribo este post. De Wikipedia:
In machine learning and natural language processing, a topic model is a type of statistical model for discovering the abstract “topics” that occur in a collection of documents. Topic modeling is a frequently used text-mining tool for discovery of hidden semantic structures in a text body.
En este caso, lo que haré será hacer web scrapping para obtener algunos titulares de prensa y analizarlos en R. En primer lugar, cargamos los paquetes.
set.seed(26)
pkgs <- c("rvest",
"httr",
"purrr",
"dplyr",
"reticulate",
"tidytext",
"ggplot2",
"tidyr",
"stringr",
"scales",
"BTM",
"wordcloud",
"reshape2",
"topicmodels")
invisible(lapply(pkgs, require, character.only = TRUE))Ahora vamos a extraer la información de los titulares de tres periódicos españoles (El País, El Diario y La Razón). Lo hacemos usando la inestimable ayuda de rvest y purrr.
# esta funcion permite leer los titulares y crear un dataframe con dos columnas (titular y periodico)
# en donde cada fila es un titular
extract_info <- function(url) {
root_site <- read_html(url)
root_site %>%
html_nodes("h2") %>%
html_text()%>%
tibble::tibble(periodico = parse_url(url)$hostname, info = .)
}
noticias <- map_df(c("https://elpais.com", "https://eldiario.es", "https://larazon.es"), extract_info)Ciertamente, el análisis textual está más desarrollado en inglés que en español. Y no es de extrañar. Por ello, vamos a traducir los textos a inglés a través de la API de Google Translate utilizando la librería de Python mtranslate. Para ello se va a usar reticulate, un espectacular paquete que permite integrar código entre R y Python.
# codigo python
from mtranslate import translate
noticias = r.noticias.copy()
noticias['info_en'] = noticias['info'].apply(lambda x: translate(to_translate=x, from_language="es", to_language="en"))Volvemos a R con el mismo dataframe pero con una columna extra con la información traducida:
noticias <- as_tibble(py$noticias)A continuación vamos a tokenizar los textos en ingles, de tal modo que queda en formato tidy (one-token-per-row).
noticias_token <-
noticias %>%
mutate(noticia_n = row_number()) %>%
unnest_tokens(word, info_en)
noticias_token## # A tibble: 4,912 x 4
## periodico info noticia_n word
## <chr> <chr> <int> <chr>
## 1 elpais.com "\nERC tensa la negociación con el PSOE a… 1 erc
## 2 elpais.com "\nERC tensa la negociación con el PSOE a… 1 tenses
## 3 elpais.com "\nERC tensa la negociación con el PSOE a… 1 the
## 4 elpais.com "\nERC tensa la negociación con el PSOE a… 1 negotia…
## 5 elpais.com "\nERC tensa la negociación con el PSOE a… 1 with
## 6 elpais.com "\nERC tensa la negociación con el PSOE a… 1 the
## 7 elpais.com "\nERC tensa la negociación con el PSOE a… 1 psoe
## 8 elpais.com "\nERC tensa la negociación con el PSOE a… 1 by
## 9 elpais.com "\nERC tensa la negociación con el PSOE a… 1 voting
## 10 elpais.com "\nERC tensa la negociación con el PSOE a… 1 for
## # … with 4,902 more rowsEstas serían las palabras más repetidas en los medios analizados en el momento en el que escribo este post:
noticias_token %>%
anti_join(stop_words, by = "word") %>%
count(word, sort = TRUE) %>%
mutate(word = reorder(word, n)) %>%
dplyr::filter(n > 5) %>%
ggplot(aes(word, n)) +
ggplot2::labs(
y = "# veces que aparece",
x = "Palabra",
title = "Palabras más repetidas (> 5 veces)",
caption = "\n@jlopezper"
) +
geom_col() +
coord_flip() +
theme_minimal()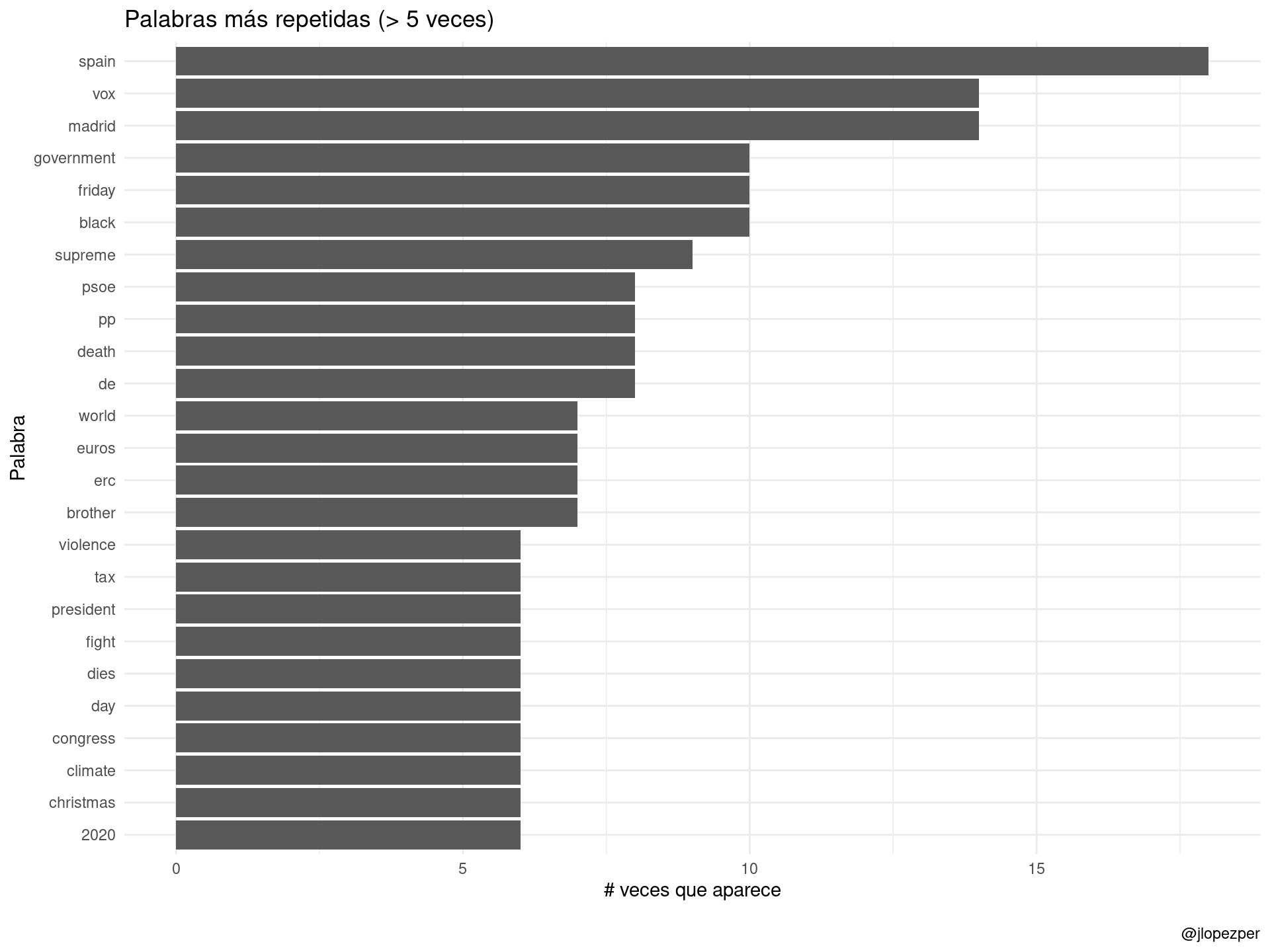
Y rápidamente, por no repetirnos con el post anterior, hacemos un análisis de sentimiento a utilizando el diccionario de Bing Liu’s. Como siempre, hay que analizarlo con cautela porque, por ejemplo, sospecho que supreme es la traducción literal de Tribunal Supremo.
noticias_token %>%
inner_join(get_sentiments("bing"), by = "word") %>%
count(word, sentiment, sort = TRUE) %>%
acast(word ~ sentiment, value.var = "n", fill = 0) %>%
comparison.cloud(colors = c("gray20", "gray80"),
max.words = 100)
Finalmente, y como objetivo principal de este post, vamos a realizar algo de topic modeling para los titulares de prensa. Uno de los algoritmos más utilizados es el LDA. Tal y como explican Julia Silge y David Robinson en Text Mining with R:
Latent Dirichlet allocation (LDA) is a particularly popular method for fitting a topic model. It treats each document as a mixture of topics, and each topic as a mixture of words. This allows documents to “overlap” each other in terms of content, rather than being separated into discrete groups, in a way that mirrors typical use of natural language.
[…]
Latent Dirichlet allocation is one of the most common algorithms for topic modeling. Without diving into the math behind the model, we can understand it as being guided by two principles.
Every document is a mixture of topics. We imagine that each document may contain words from several topics in particular proportions. For example, in a two-topic model we could say “Document 1 is 90% topic A and 10% topic B, while Document 2 is 30% topic A and 70% topic B.”
Every topic is a mixture of words. For example, we could imagine a two-topic model of American news, with one topic for “politics” and one for “entertainment.” The most common words in the politics topic might be “President”, “Congress”, and “government”, while the entertainment topic may be made up of words such as “movies”, “television”, and “actor”. Importantly, words can be shared between topics; a word like “budget” might appear in both equally.
Evidentemente, a lo que ellos se refieren como documentos son los titulares de prensa. En el libro, por ejemplo, ponen algún ejemplo donde los documentos son capítulos de libros o noticias completas de prensa. En este caso, los titulares son notablemente más cortos y por tanto veremos que se hace más complejo separar los topics.
En primer lugar, hay que transformar los datos que tenemos. Debemos trabajar con matrices término-documento. En esta matriz:
- Cada fila representa un documento (el identificador del titular)
- Cada columna representa un término
- Cada valor contiene el número de veces que aparece ese término en ese documento.
La información que podemos extraer cuando convertimos la información en formato tidy una matriz término-documento es bastante interesante. En particular, Non-/sparse entries hace referencia a la proporción de ceros que tenemos en la matriz (en donde Sparsity es el resultado de 1 menos el cociente anterior). También se puede ver que la palabra con más longitud entre todos los términos es de 20 caracteres.
# convertimos a document-term matrix
noticias_token_dtm <-
noticias_token %>%
anti_join(stop_words, by = "word") %>%
count(noticia_n, word, sort = TRUE) %>%
cast_dtm(noticia_n, word, n)
noticias_token_dtm## <<DocumentTermMatrix (documents: 439, terms: 1735)>>
## Non-/sparse entries: 2582/759083
## Sparsity : 100%
## Maximal term length: 20
## Weighting : term frequency (tf)Ahora entrenamos el LDA (a modo de ejemplo, con cuatro topics). El modelo calcula la probabilidad de que ese término se genere a partir de ese tema. Por ejemplo, tal y como se ve en el siguiente resultado, el término rights parece ser generado con mayor probabilidad por el topic 3.
# se entrena el LDA
ap_lda <- LDA(noticias_token_dtm, k = 4, control = list(seed = 26))
# sacamos los betas
ap_topics <- tidy(ap_lda, matrix = "beta")
ap_topics## # A tibble: 6,940 x 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 rights 5.53e-241
## 2 2 rights 1.61e-241
## 3 3 rights 3.16e- 3
## 4 4 rights 5.65e-241
## 5 1 management 5.99e- 3
## 6 2 management 6.93e- 41
## 7 3 management 7.21e-221
## 8 4 management 1.61e- 3
## 9 1 nutrition 1.83e-225
## 10 2 nutrition 3.00e- 3
## # … with 6,930 more rowsAhora bien, vamos a ver los términos más probables para cada topic. La verdad es que no se ve nada muy claro y creo que cualquier interpretación es muy aventurada.
ap_top_terms <- ap_topics %>%
group_by(topic) %>%
top_n(5, beta) %>%
ungroup() %>%
arrange(topic, -beta)
ap_top_terms %>%
mutate(term = reorder_within(term, beta, topic)) %>%
ggplot(aes(term, beta, fill = factor(topic))) +
geom_col(show.legend = FALSE) +
facet_wrap(~ topic, scales = "free") +
coord_flip() +
scale_x_reordered() +
theme_minimal()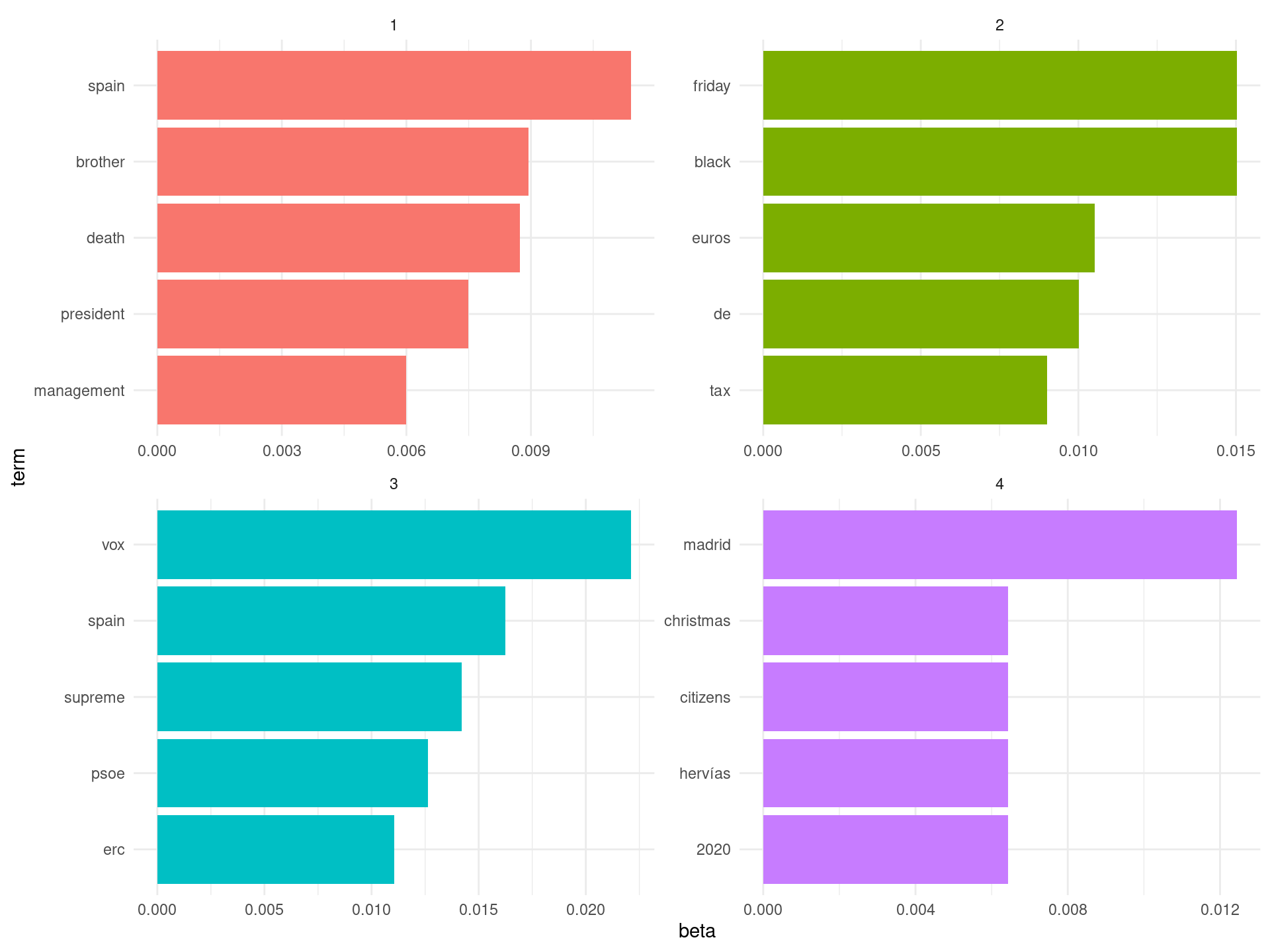
Vamos a hacer un último experimento con otros datos y con otro modelo.
- Vamos a utilizar información de un periódico con información en inglés, concretamente del diario express.co.uk. Esto permite puentear el paso del traductor.
- En segundo lugar, vamos a cambiar la metodología. En este caso se utilizará Biterm Topic Modelling (BTM), diseñado precisamente para textos cortos como los que disponemos.
extract_info <- function(url) {
root_site <- read_html(url)
root_site %>%
html_nodes('h4') %>%
html_text()%>%
tibble::tibble(periodico = parse_url(url)$hostname, info = .)
}
# extraccion de noticias
noticias <- map_df(c("https://express.co.uk/news"), extract_info)# tokenizacion
noticias_token <-
noticias %>%
mutate(documento = paste0(periodico, "_", row_number())) %>%
unnest_tokens(word, info)Entrenamos el modelo y vemos los resultados. Me parece que aquí los resultados son mejores, en donde se ven referencias a la corona británica (topic 3), de política británica (topic 4), de noticias meteorólogicas/ambientales (topic 2) y otro último topic no muy definido, en donde parece haber un batiburrillo de posibles temas (topic 1).
set.seed(26)
model_btm <- BTM(noticias_token[, c("documento", "word")] %>% anti_join(stop_words, by = "word"), k = 4, beta = 0.5, iter = 1500, trace = 500)## 2020-04-18 20:53:37 Start Gibbs sampling iteration 1/1500
## 2020-04-18 20:53:38 Start Gibbs sampling iteration 501/1500
## 2020-04-18 20:53:38 Start Gibbs sampling iteration 1001/1500topicterms <- terms(model_btm, top_n = 10)
topicterms %>%
bind_rows(.id = "topic") %>%
mutate(token = reorder_within(token, probability, topic)) %>%
ggplot(aes(token, probability, fill = factor(topic))) +
geom_col(show.legend = FALSE) +
facet_wrap(~ topic, scales = "free") +
coord_flip() +
scale_x_reordered() +
theme_minimal()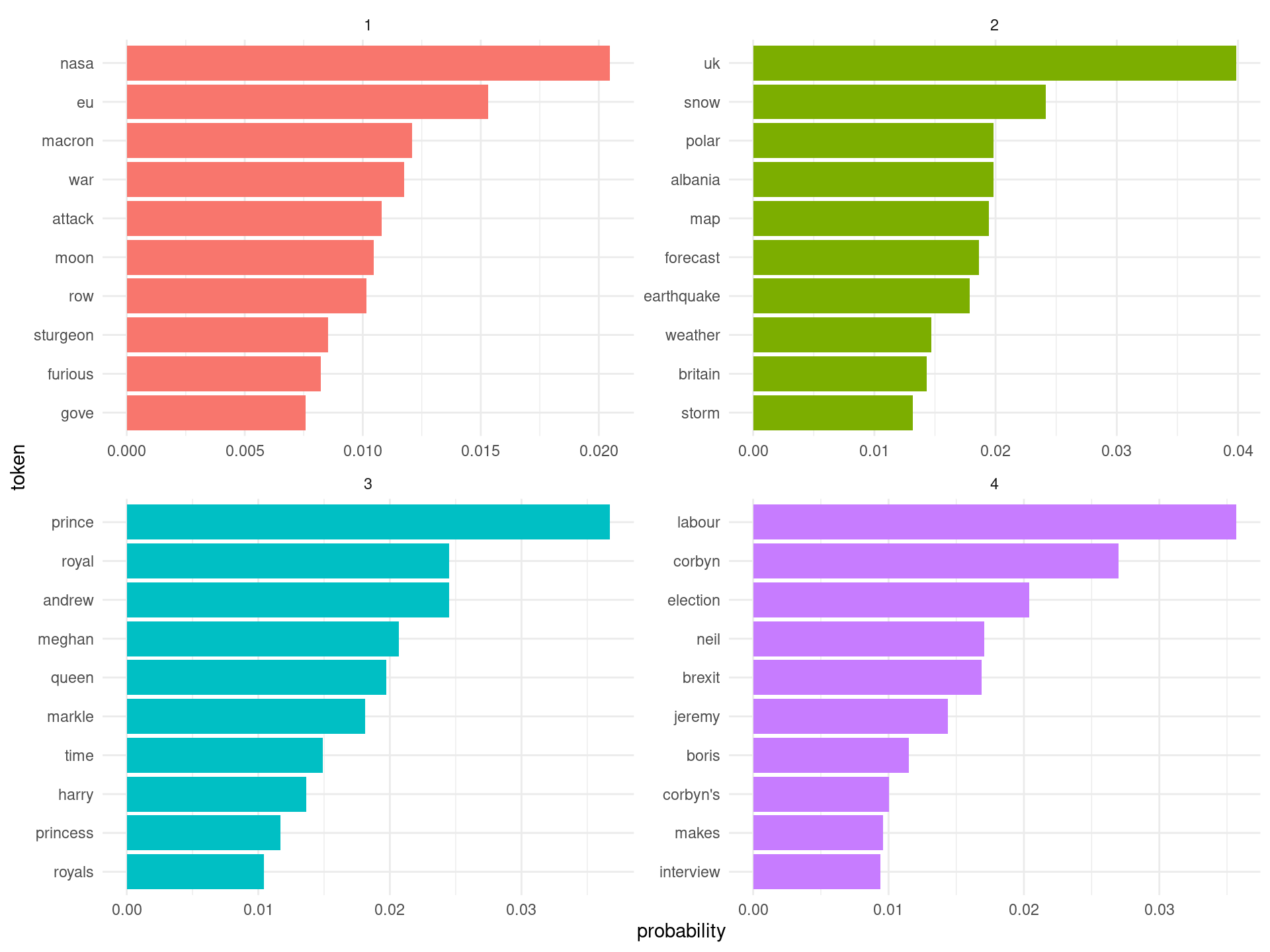
En definitiva, esto solo pretende ser una aproximación un tanto naive a un tema que desde luego da para muchísimo.